
急速に進化する人工知能の分野において、DeepSeekは高度な言語モデルの開発における主要なプレーヤーとして台頭してきました。特にDeepSeek-V2シリーズにおける革新的なアプローチは、効率性とパフォーマンスの限界を押し広げ、AI駆動のさまざまなアプリケーションに最先端のソリューションを提供しています。
アーキテクチャの革新
DeepSeekモデルには、際立った特徴となるいくつかの重要なアーキテクチャの進歩が組み込まれています。
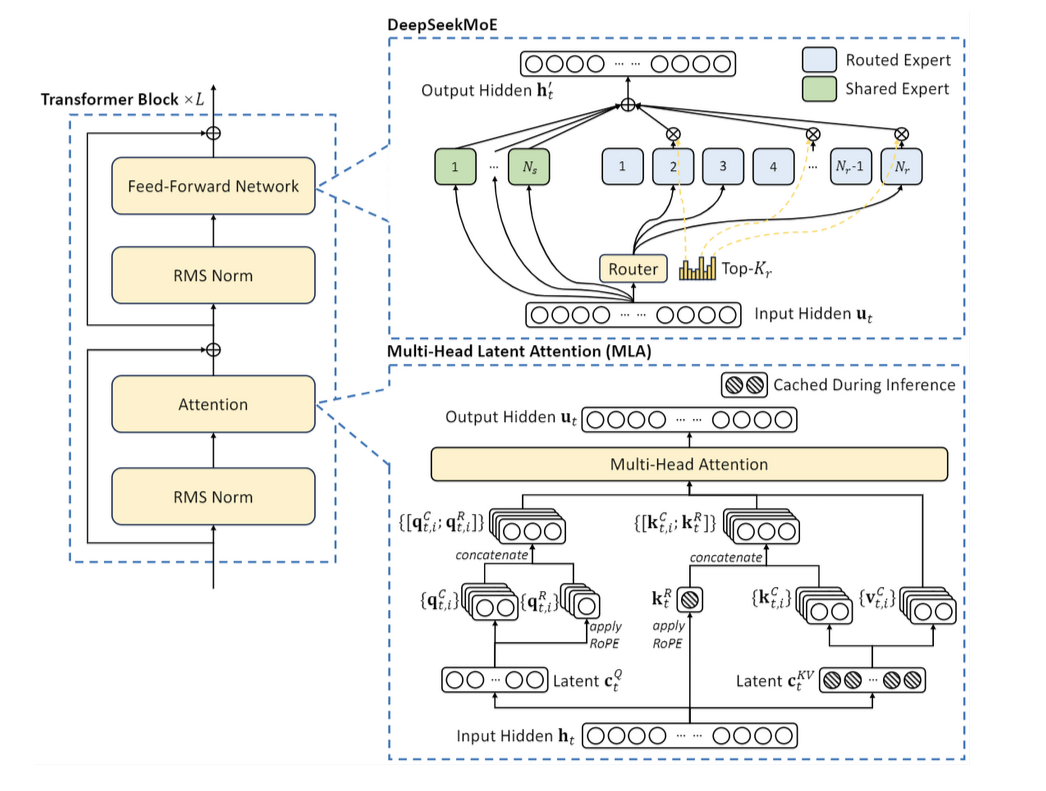
- マルチヘッド潜在アテンション(MLA):この手法はキーと値のペアを圧縮し、推論時間のボトルネックを削減し、より高速な処理を実現します。
- 混合エキスパート(MoE):トークンごとのパラメータの選択的活性化を可能にし、堅牢なパフォーマンスを維持しながら、計算効率を大幅に最適化します。
- 拡張文脈長:DeepSeek-V2モデルは拡張文脈長を処理できるため、より複雑なクエリを処理し、より一貫性のある出力を生成できます。
DeepSeekモデルの理解
DeepSeekは、自然言語処理(NLP)、コーディング、数学的推論など、さまざまなAIタスクに優れた性能を発揮するように設計された大規模言語モデルの集合です。これらのモデルは、混合エキスパート(MoE)アーキテクチャと微調整技術を組み込んでおり、効率性と拡張性が大幅に向上しています。
DeepSeek-R1
DeepSeekは、第一世代の推論モデルであるDeepSeek-R1-ZeroとDeepSeek-R1を発表しました。DeepSeek-R1-Zeroは、事前ステップとして教師あり微調整(SFT)なしで大規模強化学習(RL)により訓練されたモデルであり、推論において優れた性能を発揮します。RLにより、DeepSeek-R1-Zeroは自然に、強力かつ興味深い推論行動を多数示すようになりました。しかし、DeepSeek-R1-Zeroは、際限のない繰り返し、読みづらさ、言語の混合などの課題に直面しています。
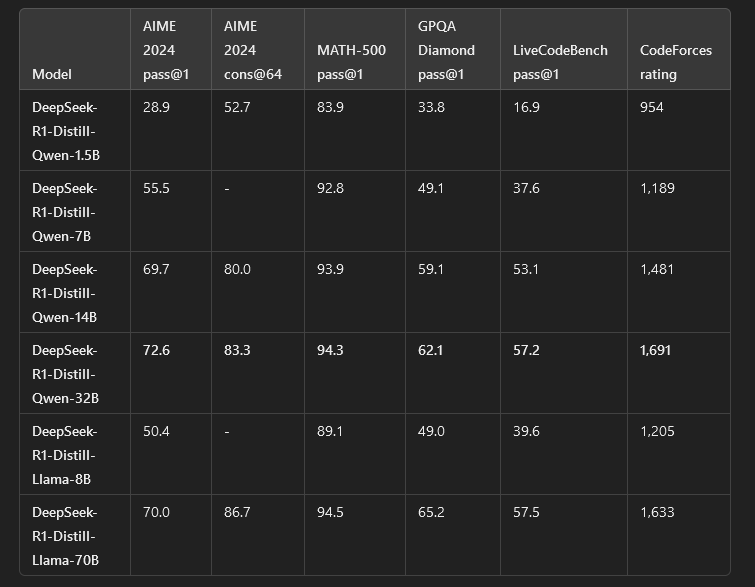
これらの問題に対処し、推論性能をさらに向上させるため、DeepSeekは、RLの前にコールドスタートデータを組み込むDeepSeek-R1を導入しました。DeepSeek-R1は、数学、コード、推論タスクにおいて、OpenAI-o1と同等の性能を達成しています。研究コミュニティを支援するため、DeepSeekはDeepSeek-R1-Zero、DeepSeek-R1、およびLlamaとQwenをベースにDeepSeek-R1から抽出した6つの高密度モデルをオープンソース化しました。DeepSeek-R1-Distill-Qwen-32Bは、さまざまなベンチマークでOpenAI-o1-miniを上回り、高密度モデルの新たな最先端の結果を達成しました。
ポストトレーニング:ベースモデルにおける大規模強化学習
DeepSeekは、事前ステップとして教師あり微調整(SFT)に頼ることなく、強化学習(RL)をベースモデルに直接適用します。このアプローチにより、モデルは複雑な問題を解決するための連鎖思考(CoT)を探索することが可能となり、DeepSeek-R1-Zeroの開発につながりました。
DeepSeek-R1-Zeroは、自己検証、内省、長いCoTの生成などの能力を示し、研究コミュニティにとって重要なマイルストーンとなりました。特に注目すべきは、SFTを必要とせずに、LLMの推論能力が純粋にRLによって強化できることを検証した初のオープンな研究であることです。この画期的な成果は、この分野における今後の進歩への道筋をつけるものです。
DeepSeekは、DeepSeek-R1を開発するためのパイプラインを導入しました。このパイプラインには、改善された推論パターンを発見し、人間の好みに合わせることを目的とした2つのRLステージと、モデルの推論および非推論能力の種となる2つのSFTステージが組み込まれています。DeepSeekは、このパイプラインにより、より優れたモデルが作成され、業界に貢献できると考えています。
モデル蒸留
DeepSeekは、より大きなモデルの推論パターンをより小さなモデルに凝縮することができ、小規模なモデルでRLによって発見された推論パターンと比較して、より優れたパフォーマンスを実現できることを示しています。オープンソースのDeepSeek-R1およびそのAPIは、今後より優れた小規模モデルを凝縮する上で、研究コミュニティに貢献するでしょう。
DeepSeek-R1によって生成された推論データを使用して、DeepSeekは研究コミュニティで広く使用されている複数の緻密なモデルを微調整しました。評価結果は、抽出されたより小さな高密度モデルがベンチマークで非常に優れた性能を発揮することを示しています。DeepSeekは、Qwen2.5およびLlama3シリーズに基づく抽出された15億、70億、80億、140億、320億、700億のチェックポイントをコミュニティにオープンソースとして提供しています。
DeepSeek-R1の評価
DeepSeek-R1の評価では、さまざまなベンチマークにおけるモデルのパフォーマンスを測定します。このモデルは混合エキスパート(MoE)アーキテクチャを使用し、合計671Bのパラメータのうち37Bをアクティブ化します。英語のカテゴリでは、DeepSeek-R1はMMLU(Pass@1)で90.8、MMLU-Pro(EM)で84.0を獲得しました。DROP (3-shot F1)では92.2で他を凌駕し、IF-Eval (Prompt Strict)では83.3を達成しています。GPQA-Diamond (Pass@1)では71.5、SimpleQA (Correct)では30.1を達成しています。FRAMES (Acc.) のスコアは82.5、AlpacaEval2.0 (LC-winrate)では、87.6のスコアを記録しました。
コード関連のベンチマークでは、DeepSeek-R1はArenaHard (GPT-4-1106)で92.3、LiveCodeBench (Pass@1-COT)で65.9と、高いパフォーマンスを示しました。Codeforces (百分位) では、96.3位、Codeforces (レーティング) では2,029点です。これらの結果は、英語の理解力とコーディングタスクの両方においてDeepSeek-R1の優れた性能を示しており、複数のAI評価ベンチマークにおけるその有効性を証明しています。
適切なモデルの選択
- DeepSeek-R1-ZeroおよびDeepSeek-R1:高い演算能力および長い文脈ウィンドウを必要とする大規模なアプリケーションに最適です。
- DeepSeek-R1-Distillモデル:より高速な推論、より少ないメモリ使用、数学的推論やコード生成などの特定のタスクに最適です。
- Qwenベースの蒸留モデル:数学を多用するタスクおよび論理的推論に最適です。
- Llamaベースの蒸留モデル:一般的な言語理解や指示に従うことにより適している。
DeepSeek-V2
DeepSeek-V2は、費用対効果の高いトレーニングと効率的な推論を維持しながら、優れたパフォーマンスを実現するように設計された高度な混合エキスパート(MoE)言語モデルです。合計2360億のパラメータにより、1トークンあたり210億のパラメータのみが有効化され、計算効率とモデル能力の最適なバランスが確保されます。
DeepSeek-V2は、前バージョンのDeepSeek 67Bと比較して、複数のタスクとベンチマークにおいて全体的なパフォーマンスが向上し、計算コストを大幅に削減しています。 トレーニング費用を42.5%削減し、KVキャッシュ要件を93.3%削減し、最大生成スループットを5.76倍に増加させるなど、強力でありながらリソース効率の高いモデルとなっています。
DeepSeek-V2は、8.1兆のトークンで構成される広範かつ多様な高品質データセットでトレーニングされました。この大規模な事前トレーニングは、モデルの応答を洗練し、人間の意図との整合性を向上させる「Supervised Fine-Tuning(SFT)」、および意思決定能力を最適化し、自由形式の生成品質を向上させる「Reinforcement Learning(RL)」によってさらに強化されました。評価結果は、標準的なAIベンチマークと現実世界の自由形式のタスクの両方において、モデルの優れた性能を示しており、幅広い用途における有効性を証明しています。
2024年5月6日、DeepSeek-V2が正式にリリースされ、MoEベースのAIモデルにおける新たなベンチマークが設定されました。その後、2024年5月16日には、効率性を重視したより軽量なバージョンとしてDeepSeek-V2-Liteが発表されました。画期的なアーキテクチャと効率性を重視した設計により、DeepSeek-V2は最先端の言語モデルとしての地位を確立し、高いパフォーマンスを実現しながら計算コストを大幅に削減します。
モデルのアーキテクチャ
DeepSeek-V2 は、費用対効果の高いトレーニングと最適化された推論効率を確保するために、最先端のアーキテクチャ革新を組み込んでいます。
- マルチヘッド潜在アテンション(MLA):このメカニズムは、低ランクのキーバリューユニオン圧縮を採用し、推論時のキーバリューキャッシュのボトルネックを排除することで、推論効率を大幅に向上させます。
- DeepSeekMoE for Feed-Forward Networks (FFNs): 高性能な混合エキスパート(MoE)フレームワークを活用することで、DeepSeekMoEは計算コストを削減しながら、より強力なモデルのトレーニングを可能にします。
DeepSeek-V2へのアクセス方法
DeepSeek-V2は、複数のプラットフォームおよびインターフェースで利用可能な最先端の混合エキスパート(MoE)言語モデルです。 その強力なAI機能を統合しようとしている研究者、開発者、または企業の方々にとって、DeepSeek-V2にアクセスし、利用する方法はいくつかあります。
公式ウェブサイト
DeepSeek-V2 を最も簡単に利用するには、公式ウェブサイトである DeepSeek.com をご利用ください。 ここでは、モデルの機能、アップデート、潜在的な用途に関する詳細な情報を入手できます。 また、ウェブサイトでは、ユーザーが機能性を理解するためのドキュメントや使用例へのアクセスも提供しています。
Hugging Face プラットフォーム
DeepSeek-V2は、AIおよび機械学習モデルのプラットフォームとして広く利用されているHugging Faceで利用可能です。Hugging Faceでは、ユーザーはモデルをインタラクティブにテストし、事前学習済みのバージョンをダウンロードし、提供されているAPIを使用して自身のプロジェクトに統合することができます。開発者は、Hugging Faceのエコシステムを使用して、特定のタスク向けにモデルを微調整することもできます。
GitHub リポジトリ
モデルのアーキテクチャと実装について詳しく知りたい開発者のために、DeepSeek-V2 のソースコードと関連リソースは GitHubで入手できます。リポジトリには、重要なドキュメント、トレーニングデータ、構成設定が含まれており、高度なカスタマイズと展開が可能です。
API アクセス
企業や開発者は、DeepSeek API を使用して DeepSeek-V2 を自社のアプリケーションに統合することができます。 この API はモデルの機能へのアクセスを提供し、チャットボット、コンテンツ生成、コーディング支援など、さまざまな環境へのシームレスな展開を可能にします。 まず初めに、公式 API ドキュメントを参照し、認証、リクエスト形式、使用上のベストプラクティスに関するガイダンスを確認してください。
クラウドベースのプラットフォーム
DeepSeek-V2は、DeepSeekと提携してホスト型モデル推論を提供するクラウドベースのAIサービスプロバイダーを通じてアクセスすることもできます。これらのプラットフォームは、インフラストラクチャを管理することなくAIを活用したい企業に拡張可能なソリューションを提供します。提携企業やサードパーティのクラウド統合については、DeepSeekのウェブサイトをご覧ください。
評価結果
DeepSeek-V2は、英語、中国語、コード、数学関連のタスクにおける複数のベンチマークで、その前身や他の競合モデルを上回る性能を発揮しました。67Bパラメータを超えるモデルと比較した場合、DeepSeek-V2(MoE-236B)は大幅な改善を示しています。MMLUベンチマークでは78.5を達成し、DeepSeek-V1(Dense-67B)の71.3を上回り、LLaMA3 70Bの78.9に肉薄しています。同様に、BBHベンチマークでは、DeepSeek-V2は78.9を記録し、DeepSeek-V1の68.7から大幅に上昇し、LLaMA3 70Bの81.0と同等のスコアを達成しました。
中国語の評価では、DeepSeek-V2は卓越したパフォーマンスを示し、C-Evalで81.7、CMMLUで84.0を達成し、それぞれDeepSeek-V1の66.1、70.8を大幅に上回りました。HumanEvalやMBPPなどのコードベースの評価では、DeepSeek-V2はそれぞれ48.8と66.6を獲得し、DeepSeek-V1の45.1と57.4を上回る着実な改善を示しました。数学タスクでは、DeepSeek-V2はGSM8Kで79.2、一般数学で43.6を達成しており、それぞれDeepSeek-V1の63.4、18.7から大幅な改善が見られます。
16Bより小さいモデルでは、DeepSeek-V2-Lite(MoE-16B)が同等のモデルよりも顕著な優位性を示しています。これはMLA+MoEアーキテクチャを採用しており、DeepSeek 7B (Dense) および DeepSeekMoE 16B の両方を上回る性能を発揮します。MMLU ベンチマークでは、58.3 を記録し、DeepSeekMoE 16B の 45.0 および DeepSeek 7B の 48.2 を上回りました。BBHベンチマークでは、DeepSeek-V2-Liteは44.1を達成し、DeepSeek 7BとDeepSeekMoE 16Bはそれぞれ39.5と38.9で後れを取っています。
中国語の評価では、DeepSeek-V2-LiteはC-Evalで60.3、CMMLUで64.3を記録し、DeepSeek 7BとDeepSeekMoE 16Bの両方を上回り、引き続きトップを維持しています。コーディングベンチマークでも大幅に改善し、HumanEvalで29.9、MBPPで43.2を記録し、ソフトウェア開発タスクでより優れたパフォーマンスを示しています。数学関連のタスクでは、DeepSeek-V2-Liteは大幅な進歩を見せ、GSM8Kでは41.1を記録しました。これは、DeepSeek 7Bの17.4、DeepSeekMoE 16Bの18.8と比較すると大きな飛躍です。一方、一般的な数学では、17.1を記録し、前バージョンの低いスコアを上回る結果となりました。
DeepSeek-V2 チャットモデル
DeepSeek-V2 チャットモデルは、複数の分野で大幅なパフォーマンスの向上を示し、言語理解、コーディング、数学的推論において優れた能力を発揮しています。他の大規模チャットモデルと比較すると、DeepSeek-V2 Chat (SFT) はMMLUベンチマークで78.4を達成し、DeepSeek-V1 Chat (71.1) を上回り、LLaMA3 70B Instruct (80.3) に肉薄しています。強化学習強化版のDeepSeek-V2 Chat (RL) は77.8を獲得し、言語理解力の高さを維持しています。BBHベンチマークでは、DeepSeek-V2 Chat (SFT) が81.3を達成し、DeepSeek-V1 Chat (71.7) を上回り、LLaMA3 70B Instruct (80.1) をも上回りました。一方、DeepSeek-V2 Chat (RL) は79.7という高いスコアを維持しました。
中国語の評価では、DeepSeek-V2 Chat (SFT) はC-Evalで80.9、CMMLUで82.4というスコアを記録し、DeepSeek-V1 Chat (それぞれ65.2と67.8) を大幅に上回りました。強化学習版は、この傾向を維持し、C-Evalで78.0、CMMLUで81.6を達成し、中国語テキストの理解と処理における強みをさらに強化しました。コーディングタスクでは、DeepSeek-V2 Chat (SFT) がHumanEvalで76.8、MBPPで70.4を達成し、RL版ではそれぞれ81.1、72.0にまでスコアを伸ばしました。LiveCodeBenchでは、DeepSeek-V2 Chat (SFT) のパフォーマンスが28.7に向上し、RL強化モデルでは32.5に達し、以前のDeepSeekバージョンを上回る結果となりました。
数学関連のタスクでは、DeepSeek-V2 Chat (SFT) はGSM8Kで90.8を達成し、DeepSeek-V1 Chat (84.1) を大幅に上回り、優れた問題解決能力を示しました。 RLで強化されたバージョンは92.2に達し、さらなる改善を示しました。一般的な数学ベンチマークでは、DeepSeek-V2 Chat (SFT) が52.7、RL バージョンが53.9を記録し、いずれも DeepSeek-V1 Chat (32.6) を大幅に上回る結果となりました。
小規模なチャットモデルでは、DeepSeek-V2-Lite 16B Chat (SFT) がさまざまなベンチマークで以前のバージョンを上回る性能を示しました。MMLU ベンチマークでは55.7 を達成し、DeepSeek 7B Chat では49.7、DeepSeekMoE 16B Chat では47.2 でした。BBH ベンチマークでは48.1 を達成し、小規模なモデルを上回る性能を示しました。中国語のベンチマークにおける性能も注目に値し、C-Evalで60.1、CMMLUで62.5を達成し、以前のモデルのスコアを上回りました。
コーディングタスクでは、DeepSeek-V2-Lite 16B Chat (SFT) がHumanEvalで57.3、MBPPで45.8を達成し、以前のバージョンを大幅に上回る結果となりました。数学関連のタスクでは、GSM8Kで72.0を達成し、DeepSeek 7B Chat および DeepSeekMoE 16B Chat を10ポイント近く上回りました。また、一般的な数学では27.9を達成し、以前のモデルを大きく上回りました。
DeepSeek-V2 チャットモデル、特に強化学習を利用したモデルは、AI駆動の言語処理、コーディング能力、数学的推論において新たなパフォーマンス基準を設定し、以前のバージョンや競合モデルに対する優位性を示しています。

DeepSeek-V3
DeepSeek-V3は、自然言語処理の限界を押し広げることを目的として設計された、先進的な混合エキスパート(Mixture-of-Experts: MoE)言語モデルです。 その大規模なアーキテクチャと革新的なトレーニング技術により、計算効率を最適化しながら卓越したパフォーマンスを実現します。
DeepSeek-V3は、混合エキスパート(MoE)アプローチを採用しており、総計6710億のパラメータを誇りながら、各トークンにつき370億のパラメータのみを起動します。この選択的な起動により、効率的な計算リソースの利用と高いパフォーマンスが実現します。
このモデルは、マルチヘッド潜在アテンション(MLA)を統合しており、これにより、データ内の複雑なパターンを捉える能力が強化されています。この改善により、複雑なクエリのより深い理解と、より洗練されたテキスト生成が可能になります。
DeepSeek-V3の革新的な機能のひとつに、補助損失フリーの負荷分散メカニズムがあります。これにより、追加の損失関数を必要とせずに、計算負荷を公平かつ効果的に分散させることができ、トレーニングをより安定かつ効率的に行うことができます。
従来のモデルでは、1つのトークンを予測する方式を採用していましたが、DeepSeek-V3では、マルチトークン予測戦略を採用しています。このアプローチにより、処理速度とモデル全体のパフォーマンスが大幅に向上します。
トレーニングとパフォーマンス
DeepSeek-V3は、14兆8000億の高品質なトークンで構成される広範な多言語コーパスでトレーニングされています。このデータセットは主に英語と中国語で構成されており、数学およびプログラミングデータに重点的に取り組んでいます。この包括的なトレーニングにより、自然言語理解、論理的推論、コード生成など、複数の分野で優れた性能を発揮するモデルとなっています。
61層で構成され、コンテクストの長さが最大128,000トークンであるアーキテクチャにより、DeepSeek-V3は長文コンテンツをシームレスに処理できます。ベンチマーク評価では、このモデルがLlama 3.1やQwen 2.5などの競合他社を上回る性能を発揮し、GPT-4oやClaude 3.5 Sonnetと同等レベルの結果を達成していることが示されています。
アクセス性とライセンス
DeepSeek-V3はオープンソースであり、コードとモデルの重みは一般公開されています。モデルはコードのMITライセンスでリリースされており、モデルの重みは責任ある使用を確保するための特定のライセンス契約によって管理されています。
DeepSeek-V3.1
DeepSeek V3.1はDeepSeekの最新オープンウェイトハイブリッド推論モデルであり、対話、コーディング、ツール使用機能を単一の統合アーキテクチャに統合しています。シンプルなプロンプト切り替えで「思考モード」と「非思考モード」の両方をサポートし、ユーザーは深い推論と高速応答の選択が可能です。内部構造では、V3.1は専門家混合モデル(MoE)設計を採用(総パラメータ数671億、トークンあたり約37億が活性化)。最大128Kトークンの拡張コンテキストウィンドウをサポート。モデルのトレーニングプロセスでは、長文コンテキストのスケーリングとトレーニング後の調整を重視し、ツール呼び出し、多段階推論、一貫性の向上を図り、応答品質を維持しつつレイテンシ削減を目指しています。
性能ベンチマークと比較優位性
DeepSeek V3.1は、多くのベンチマークスイートにおいて、特にコーディングと推論タスクで以前のバージョンを大きく上回る成果を示しています。例えば、SWE-bench Verifiedコーディングベンチマークでは約66.0%の合格率を達成し、DeepSeek R1の44.6%を上回っています。コミュニティ評価では、より広範なプログラミング課題スイートで71.6%の合格率を達成し、Claudeなどのモデルをわずかに上回り、一部のテストでは同等またはそれを超える結果を示しています。より一般的な推論・検索タスクにおいても、V3.1はV3およびR1を上回っています:独立テストにおいてTerminal-Bench、BrowseComp、クロスソース統合ベンチマーク(例:xbench-DeepSearch)で高得点を記録。DeepSeek社によれば、V3.1の「思考モード」は専用推論モデルR1に匹敵する解答品質を達成しつつ、応答速度を向上させているとのことです。
DeepSeek-V3.1-Terminus
DeepSeek-V3.1-Terminusは、実際のユーザーフィードバックに基づき安定性・一貫性・能動的性能を強化するためリリースされたDeepSeek V3.1モデルの改良版です。アーキテクチャの大幅な見直しではなく、TerminusはV3.1の強みを磨き上げ、言語の一貫性(中国語と英語の混在の削減、奇妙な文字アーティファクトの回避)を改善し、内部の「コードエージェント」と「検索エージェント」フレームワークを強化して、実際のタスクにおけるツール使用の信頼性を高めることに焦点を当てています。モデルは従来のハイブリッド推論構造(思考モード/非思考モードの2モード)と128Kトークンコンテキストウィンドウを維持しつつ、ベンチマーク全体でより安定した出力を目指しています。
Terminusの性能ベンチマークと改善点
ベンチマーク比較において、DeepSeek-V3.1-Terminusは特にエージェント的ツール使用タスクで顕著な向上を示しています。例:
- BrowseComp(ウェブ検索/ナビゲーション):30.0 → 38.5
- SimpleQA:93.4 → 96.8
- SWE Verified:66.0 → 68.4
- Terminal-bench:31.3 → 36.7
ツールを使用しない推論タスクでは改善幅は控えめです:例えば、MMLU-Proは84.8 → 85.0、GPQA-Diamondは80.1 → 80.7、Humanity’s Last Examは15.9 → 21.7とより大きな上昇を示しています。一部のコーディング指標(例:Codeforces)ではわずかな後退(例:2091 → 2046)が見られる。これはツール統合性能を向上させるためのトレードオフかもしれない。
DeepSeek-V3.2
DeepSeek-V3.2は、DeepSeekの推論優先モデルラインナップにおける最新の進化形であり、V3.2-Expの後継モデルとして正式にリリースされ、アプリ、Web、APIプラットフォームで利用可能となりました。エージェントを念頭に設計された本リリースは、構造化された推論、長文脈理解、ツール使用への思考のネイティブ統合を重視しています。これと並行して、複雑な推論の限界を押し広げることを目的とした高演算能力のAPI専用モデル「DeepSeek-V3.2-Speciale」が導入されました。本リリースではさらに、1,800以上の環境と85,000以上の複雑な指示を網羅する大規模エージェント訓練データ合成アプローチを初公開。これにより、ツールの有無にかかわらず効果的な推論が可能となります。
ベンチマークと性能
性能面では、DeepSeek-V3.2は推論の深さと効率性のバランスを実現し、GPT-5クラスシステムに匹敵する性能を持つ強力な日常使用モデルとして位置付けられる。DeepSeek-V3.2-Specialeは最大推論能力に焦点を当て、Gemini-3.0-Proなどのトップクラスモデルに匹敵する性能を発揮する。学術・競技向けエリートベンチマークにおいて、V3.2-SpecialeはIMO(国際数学オリンピック)、CMO(中国数学オリンピック)、ICPCワールドファイナル、IOI 2025で金メダル級の結果を達成。数学・アルゴリズム・複雑問題解決における卓越した強さを示した。トークン使用量増加によるリソース消費増はあるものの、これらの成果はDeepSeekが高度な推論とエージェント指向AI研究において最先端の地位にあることを強調している。
DeepSeek Coder
DeepSeek Coderは、80以上のプログラミング言語にわたる2兆トークンで事前学習されており、多様なコーディングパターンの包括的な理解を保証します。13億、57億、67億、330億など、さまざまなモデルサイズを提供しており、異なる計算およびアプリケーションのニーズに対応しています。
16Kのウィンドウサイズにより、DeepSeek Coderはプロジェクトレベルのコードの完成とインフィルをサポートし、広範なコード構造の理解と生成能力を強化します。オープンソースのコードモデルの中でも最先端の性能を誇るDeepSeek Coderは、研究および商業利用が可能であり、高度なコード生成技術をより身近なものにしています。
DeepSeek Coderの使用方法
DeepSeek Coderは、AIを駆使した先進的なコード生成、補完、インフィリングツールです。 以下の手順に従って、インストールし、効果的にご利用ください。
システム要件を確認する
- ハードウェア:特に大規模なモデルの場合、高性能GPUの使用を推奨します。
- ソフトウェア:Python 3.8以降がシステムにインストールされていることを確認してください。
必要なソフトウェアをインストールする
- Python:公式ウェブサイトからPythonをダウンロードし、インストールします。
- Git: 公式ページからGitをインストールしてください。
仮想環境のセットアップ
ターミナルまたはコマンドプロンプトを開きます。
- プロジェクトディレクトリに移動します: cd /path/to/your/project
- 仮想環境を作成する:python -m venv deepseek-env
- 仮想環境を起動します。
- Windows: deepseek-env\Scripts\activate
- macOS/Linux: source deepseek-env/bin/activate
希望するモデルをダウンロードする
システムの能力に基づいてモデルのサイズを選択します。
- 1.3Bモデル:リソースが限られたシステムに適しています。
- 5.7Bモデル:中程度のリソースが必要です。
- 6.7Bモデル:より高い演算能力が必要です。
- 33Bモデル:最高のパフォーマンスを提供しますが、相当なリソースが必要です。
リポジトリに用意されているスクリプトを使用してモデルをダウンロードします。
DeepSeek Coder を実行
モデルを実行するには、適切なコマンドを使用します。例えば、6.7Bモデルを実行するには:python run_model.py –model deepseek-coder-6.7b
モデルをテストする
コードプロンプトを提供して、DeepSeek Coderと対話します。 例:

さらに詳しく
詳細なドキュメントおよび追加機能については、DeepSeek Coder GitHub リポジトリを参照してください。
DeepSeek Coder のパフォーマンス
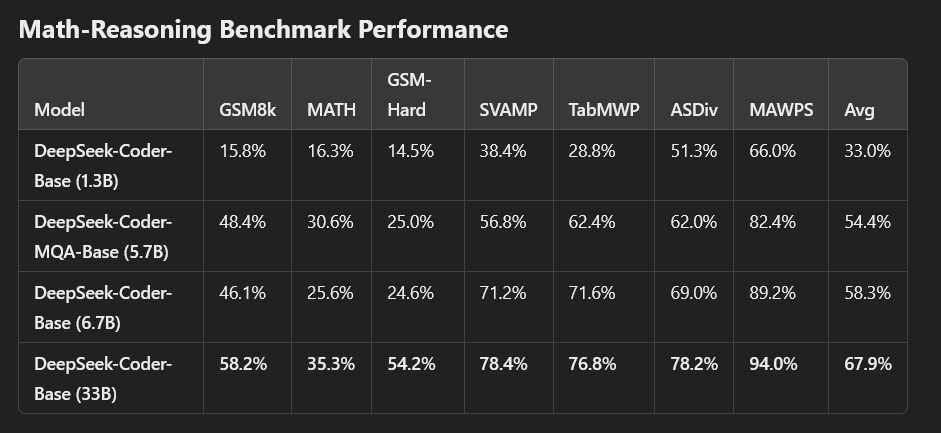
DeepSeek は、さまざまなコーディング関連のベンチマークで DeepSeek Coder を評価しました。その結果、DeepSeek-Coder-Base-33B は既存のオープンソースのコード LLM を大幅に上回るパフォーマンスを発揮することが示されました。CodeLlama-34Bと比較すると、HumanEval Python、HumanEval Multilingual、MBPP、DS-1000でそれぞれ7.9%、9.3%、10.8%、5.9%の性能向上を達成しています。注目すべきは、DeepSeek-Coder-Base-7BがCodeLlama-34Bと同等のパフォーマンスレベルに達していることです。さらに、インストラクションチューニング後、DeepSeek-Coder-Instruct-33BモデルはHumanEvalでGPT-3.5-turboを上回り、MBPPではGPT-3.5-turboと同等の結果を出しています。
DeepSeek Coderモデルは、HumanEvalベンチマークにおいて、多言語ベースモデルと指示調整モデルの両方で優れた性能を発揮しました。ベースモデルの中で、DeepSeek-Coder-Base-33Bは平均スコア50.3%でトップとなり、他のオープンソースの多言語モデルをすべて上回りました。Python(56.1%)、C++(58.4%)、Java(51.9%)、JavaScript(55.3%)で最高精度を達成しています。より小規模なDeepSeek-Coder-Base-6.7Bも平均44.7%と良好な結果を示し、C++(50.3%)とTypeScript(49.7%)で優れた結果を示しています。一方、DeepSeek-Coder-MQA-Base-5.7Bは41.3%、DeepSeek-Coder-Base-1.3Bは28.3%というスコアを記録しており、モデルサイズの増加に伴う拡張可能なパフォーマンスの向上を反映しています。
命令調整モデルでは、DeepSeek-Coder-Instruct-33Bはパフォーマンスを大幅に向上させ、平均精度69.2%という素晴らしい結果を達成しました。これはGPT-3.5-Turbo(64.9%)を上回り、GPT-4(76.5%)に迫るもので、Python(79.3%)、C++(68.9%)、JavaScript(73.9%)では特に高い精度を誇ります。DeepSeek-Coder-Instructの67億バージョンも66.1%と非常に高いスコアを記録しており、13億バージョンでは48.4%を達成しており、異なるモデルサイズにおける命令チューニングの有効性を示しています。
全体として、DeepSeek-CoderモデルはオープンソースのコードLLMの中でも最先端の性能を発揮し、命令調整版はGPT-3.5-TurboやGPT-4などのプロプライエタリなモデルに対抗できる結果を達成しています。
DeepSeekモデルの用途
DeepSeekモデルの汎用性により、さまざまな実世界での用途に適しています。
- チャットボットおよびバーチャルアシスタント:カスタマーサポートとユーザーとのやり取りの強化。
- AIによるコード生成:ソフトウェア開発とデバッグにおける開発者の支援。
- 自動コンテンツ作成:高品質の記事、レポート、および要約の生成。
- 数学的問題の解決:教育ツールと研究アプリケーションのサポート。
DeepSeek-R1が米国で警鐘を鳴らす理由
DeepSeek-R1のリリースは米国で大きな懸念を引き起こし、テクノロジー株の売りにつながりました。2025年1月27日(月)、ナスダック総合指数は3.4%下落で始まり、Nvidiaは17%下落し、時価総額は約6000億ドル減少しました。
DeepSeekの出現は、米国において、以下の主な理由により、複数の重大な懸念を引き起こしています。
コストの混乱
DeepSeekは、R1モデルを600万ドル未満で開発したと主張しています。これは、米国の大手テクノロジー企業がAIに費やした数十億ドルのほんの一部です。その低コストでの開発と手頃な価格は、OpenAIを含む米国のAI企業のビジネスモデルに直接脅威をもたらすものです。
技術的躍進 米国の規制にもかかわらず
米国は高性能AIアクセラレーターチップやGPUの中国への厳格な輸出規制を課しています。しかし、DeepSeekは、最先端の米国技術にアクセスできなくても最先端のAI開発が可能であることを実証しました。
米国のAIビジネスモデルへの挑戦
DeepSeekは、OpenAIの独自かつ有料のAIサービスとは異なり、オープンソースで無料で利用できるモデルを採用しています。これは、米国のAI業界を支配するサブスクリプションベースの収益の流れを弱体化させるものです。
地政学上の懸念
DeepSeekの進歩は中国のAI能力の向上を強化し、米国の技術的優位を脅かす。影響力のある技術投資家マーク・アンドリーセン氏は、この状況を1950年代のソビエト連邦の宇宙開発競争における躍進になぞらえ、AIの「スプートニク・モーメント」と表現した。
DeepSeekの急速な台頭は、変化する世界のAIの状況を浮き彫りにし、競争を激化させ、米国の経済および戦略上の懸念を高めている。
結論
DeepSeekはAIイノベーションの最先端にあり、効率性と有効性の限界を押し広げる高性能モデルを提供しています。最先端のアーキテクチャと優れたベンチマーク性能を備えたDeepSeekモデルは、人工知能に依存する業界に革命をもたらすでしょう。研究、コーディング、コンテンツ生成のいずれにおいても、DeepSeekの強力なモデルは、AI駆動のさまざまなアプリケーションに堅牢なソリューションを提供します。
よくある質問
DeepSeekのモデルサイズはどのくらいですか?
DeepSeekは、さまざまなサイズの複数のAIモデルを提供しています。DeepSeek-R1は、671Bのパラメータを使用するMixture of Experts (MoE) アーキテクチャを採用しており、推論時に37Bをアクティブ化します。DeepSeek-Coderはコーディングタスク用で、1Bから33Bのパラメータの範囲です。一方、Janus Proは1Bと7Bのパラメータバージョンで利用できる画像生成モデルです。
DeepSeek AIは無料で利用できますか?
はい、DeepSeek AIモデルはオープンソースで無料で利用できます。プレミアム版はサブスクリプションベースのモデルで運用されているChatGPTとは異なります。
米国製チップの制限があるにもかかわらず、DeepSeekはどのようにして高いパフォーマンスを実現しているのですか?
DeepSeekは、NvidiaのH100のような米国製高性能AIチップにアクセスすることなく、代替の計算リソースを使用して高度なAIモデルを開発しました。
DeepSeek-R1とDeepSeek-V3の価格はどのように比較されますか?
DeepSeek-V3はDeepSeek-R1よりも費用対効果が高く、入力トークンの価格はDeepSeek-R1の100万トークンあたり0.55ドルに対して、100万トークンあたり0.14ドルです。同様に、DeepSeek-V3の出力トークンの価格は100万トークンあたり0.28ドルで、DeepSeek-R1の100万トークンあたり2.19ドルよりも大幅に低くなっています。
DeepSeek-CoderはGitHub CopilotやChatGPTコードインタープリターと比較してどうですか?
DeepSeek-Coderは複数のプログラミング言語をサポートしており、GitHub Copilotと同様に効率的なコードを生成できますが、オープンソースのアクセシビリティに重点を置いています。
DeepSeekはChatGPTよりも優れていますか?
DeepSeekとChatGPTのどちらを選択するかは、お客様のニーズによって異なります。DeepSeekは、その正確性により、コーディングや数学などの技術的なタスクに優れています。ChatGPTは、その汎用性と幅広い機能により、創造的で会話的な用途に適しています。
DeepSeek AIは、ChatGPTのようにコンテンツに制限を課しますか?
はい、DeepSeekは、特に政治的に微妙なトピックに関して、中国の規制に準拠した厳格なモデレーションポリシーを適用しています。

